
Auf dem #HeartsandMinds Barcamp bei Microsoft konnte ich mich mit Kolleg*innen aus der Branche über ein Thema austauschen, dass mich aktuell beschäftigt: Die datengetriebene Steigerung der “Employee Experience” in der Kommunikation. Meine Gedanken aus der Präsentation halte ich hier fest.
Die Verbesserung der “Employee Experience” ist eine der größten Herausforderungen, die Deloitte 2019 für Unternehmen identifiziert hat. Laut dem Deloitte Global Human Capital Trends Berichts sehen 28 Prozent der Befragten es als eines der drei dringendsten Probleme, mit denen ihre Organisation aktuell konfrontiert wird.
Der Grund ist einfach: Laut einer Untersuchung des MITs erzielen Unternehmen mit guter “Employee Experience” 25% höhere Gewinne.
Persönlich zugeschnitten
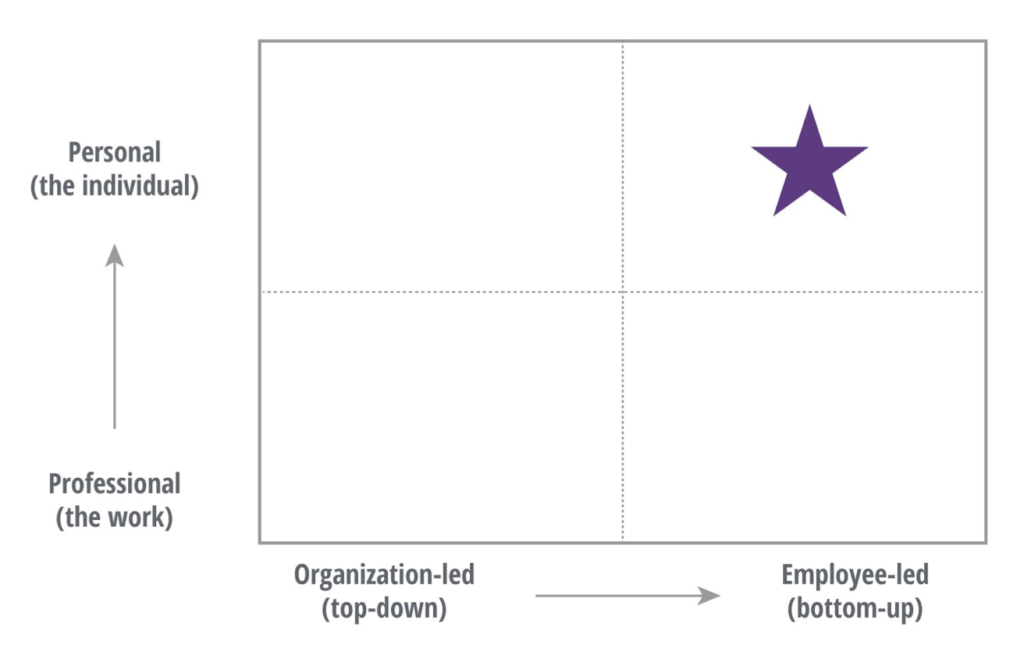
Deloitte schlägt eine persönliche und von den Mitarbeiter*innen gesteuerte Erfahrung und somit auch Kommunikation vor.
In meiner zweiten Woche als Data Analyst bei Siemens fand ich mich in einem Meeting mit genau diesem Thema wieder: Wie können wir die Belegschaft in verschiedene Zielgruppen strukturieren um sie besser zu erreichen?
Meine Vorgehensweise
Als gestandener Kommunikationsprofi mit unfassbar vielen Jahren Berufserfahrung habe ich erst einmal gegoogelt und bin auf einen Artikel von HR Technologist gestoßen, der vier Schritte zur Entwicklung von “Employee Personas” beschreibt.

Als der Analyst, der ich vorgebe zu sein (bis jetzt hat mich keiner enttarnt, sag es nicht meinem Boss), war ich glücklich, dass sich jeder Schritt um Daten dreht. Also recherchierte ich erst einmal alle passenden Daten, die es im Unternehmen so gibt.
Sammeln der Datenquellen
Mein erster Blick fiel auf die übliche Mitarbeiter*innenbefragung, die bei Siemens mehrmals im Jahr durchgeführt wird. Bei 380.000 Siemensianern – ja so nennt man sich dort – kommen einige Daten zusammen.
Zudem ist bei Siemens das interne soziale Netzwerk Yammer von Microsoft im Einsatz. Meine Hoffnung ist, dass die Interaktionsdaten der Mitarbeiter*innen bei Yammer ebenfalls Aufschluss über die verschiedenen Persönlichkeiten geben.

Außerdem gibt es im Team Digital Communications aktuell eine Hand voll spannender Projekte, die sich oft um künstliche Intelligenz und ihren Einsatz für personalisierte News-Feeds drehen. So zum Beispiel das Projekt Coffee Mug, das Mitarbeiter*innen individuell mit Informationen aus verschiedenen Quellen versorgt. Internen wie externen.
Zusammengefasst sind das also Daten aus Umfragen, dem Interaktionsverhalten im internen sozialen Netzwerk und dem Konsumverhalten von Nachrichten. Nicht schlecht!
Gliederung in bekannte Modelle
Im nächsten von HR Technologist beschriebenen Schritt geht es um das Finden von Datengruppen. Zu diesem Zweck werde ich alle Datenpunkte in eine Business Intelligence wie Power BI schieben und diese Gruppen identifizieren lassen. Die Frage ist, ob sie Sinn ergeben werden. Und ob sie sich in eine Art Modell gliedern lassen.
Zu diesem Zweck habe ich schon Mal verschiedene Modelle recherchiert. Aus dem Marketing kennt man schon das Modell der Personas. Also fiktionale Personen, die stellvertretend für eine Zielgruppe stehen.

Eine wohl gängige Strukturierung ist eine hierarchische Gliederung von Fontline Workers bis zum Top-Level Management. Eine genauere Beschreibung der hierarchischen Stufen habe ich dem Artikel vom Institute for Public Relations entnommen.

Ein weiteres Modell, das meine Recherche ausgespuckt hat, ist die Adoption Curve, die ich noch aus Crossing the Chasm von Geoffrey Moore kenne, dem einzigen Marketing-Buch das ich je gelesen habe. Die Adoption Curve beschreibt die Einführung oder Annahme eines neuen Produkts oder einer neuen Innovation gemäß den demografischen und psychologischen Merkmalen definierter Anwendergruppen.

Einfach gesagt gibt es eine kleine Personenanzahl, die offen für Innovation ist und schnell aufspringt, eine Mehrheit, die sich danach eventuell überzeugen lässt und wieder eine kleinere Menge sogenannter “Laggards”, die sich nur sehr zaghaft oder vielleicht niemals auf Neuerungen einlassen.
Am besten erklärt das Moore selbst anhand eines anschaulichen Beispiels:)
Könnte funktionieren
Viele mögliche Daten, ein paar praktische Modelle. Das ist der aktuelle Stand meiner Recherche. Mein Bauchgefühl sagt mir, dass sich die Daten gut in das Kurvenmodell einordnen lassen. Eventuell mit ein paar Anpassungen der Gruppen. Tilmann Sies von Sepago kommentierte nach meiner Session, dass sie das Modell auch schon erfolgreich genutzt haben. Das könnte also funktionieren… ich werde dann ein Update posten!
Danke auch an alle anderen, die sich mit mir. nicht nur zu diesem Thema, ausgetauscht haben. Und danke an Bianca und das ganze Microsoft-Team, für dieses tolle Barcamp!
 wpDiscuz
wpDiscuz
Your article helped me a lot, is there any more related content? Thanks!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.